
 发布内容
发布内容









无需重训练,CAD原型匹配实现3D打印零件智能识别与分类
发布时间:03-18 20:08
来自鲁汶大学、3D打印软件与服务公司Materialise以及工业智能眼镜开发商Iristick的研究人员,共同提出了一种新颖的零件识别方法。

该方法旨在解决增材制造后处理流程中高度依赖手工操作的实际难题,即多个零件在一次构建后混合,导致需要手动分类和识别。
在一篇发表于arXiv的论文中描述的系统,其核心创新在于利用物体的CAD模型,在制造后识别打印出的实体零件。
该方法的关键优势在于,每次有新零件投入生产时,无需重新训练视觉模型即可对其进行分类。
在提出的工作流程中,佩戴智能眼镜的工作人员拿起一个物体并拍摄图像,随后系统会提供识别支持。
该方法并非在引入新零件时重新训练模型,而是利用CAD模型渲染出的多个视图为每个物体构建一个原型表征。
在推理识别时,系统将真实拍摄的照片与这些预先构建的原型进行比较,从而确定类别。
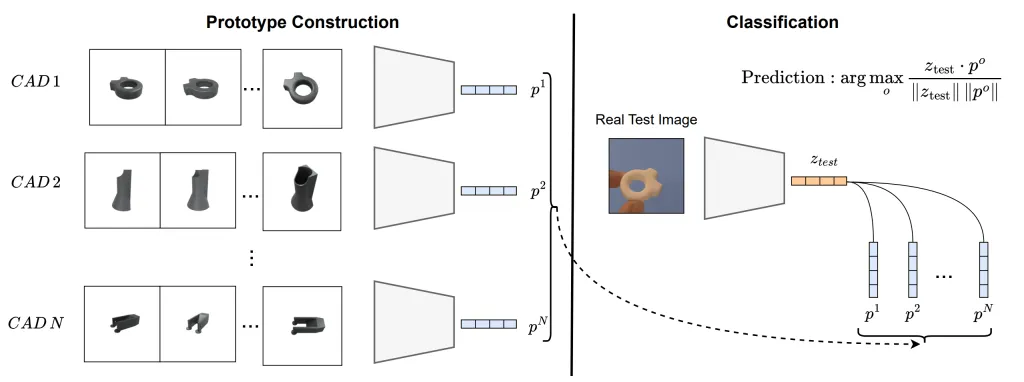
只要新物体的CAD模型可用,这种方法就免除了引入新物体时重新训练模型的需要。
这种基于原型的方法将每个物体表示为从其模型多个渲染视图导出的特征向量。
捕获的真实图像被编码到同一特征空间,并通过计算余弦相似度与原型进行比较,最接近的匹配即预测类别。
这种设计使模型与固定的物体类别解耦,允许它在任意零件集合上运行,前提是拥有相应的CAD模型,且无需额外训练。
为了评估该方法,研究人员创建了一个名为“ThingiPrint”的公开数据集。
该数据集将CAD模型与其3D打印实体的照片配对,旨在为评估相关算法提供一个基准。
ThingiPrint数据集从Thingi10K数据集中随机选择了100个模型。
每个模型均使用Sindoh S100工业选择性激光烧结系统和白色PA12粉末制造。
随后,研究人员使用智能眼镜在手动旋转物体的情况下,为每个物体拍摄约10张照片,共产生1,000张图像。
此外,研究人员通过Prusa MK4桌面系统使用白色PLA线材重新打印了其中20个物体,并额外捕获了200张图像,使照片总数达到1,200张。

该数据集旨在反映真实的后处理条件,即从多个视角拍摄手持物体。
研究评估了包括CLIP、ResNet50和DINOv2在内的多个模型,以及使用额外合成渲染图像微调后的版本。
在预训练模型中,DINOv2实现了61.8%的Top-1识别准确率,而ResNet50为35.9%,CLIP为27.1%。
经过微调后,基于DINOv2的模型性能提升至76.5%的Top-1准确率和94.0%的Top-5准确率。
训练过程采用了一种旨在产生旋转不变表征的对比目标,确保同一物体的不同视图映射到相似的特征。
没有这个旋转不变目标时,微调的DINOv2达到68.9%的Top-1准确率;加入该目标后,性能提升至76.5%。
对视觉相似或对称物体的实验显示,所有模型的总体准确率较低,微调的DINOv2模型达到63.4%的Top-1准确率。
在20个物体的子集上进行的跨打印机测试显示,同一零件的工业和桌面打印件之间差异有限。
这表明由表面纹理和反射率变化引起的域偏移较小。
研究结果还表明,当基于更多数量的渲染视图构建原型、当视点均匀采样而非随机采样、以及在推理时聚合同一物体的多张真实图像时,分类准确率会提高。

这些发现表明,基于CAD的原型匹配方法能够在无需重新训练的情况下,实现对后生产增材制造工作流程中新零件的分类。
这项研究由Fanis Mathioulakis, Gorjan Radevski, Silke GC Cleuren, Michel Janssens, Brecht Das, Koen Schauwaert和Tinne Tuytelaars共同撰写。
论文题为《无需重新训练即可分类新型3D打印物体:迈向增材制造的后生产自动化》。
 点赞
点赞
 反对
反对
 收藏
收藏
 分享
分享


AM易道
读懂3D打印卓越与演变之道
 标签
标签

 读懂3D打印卓越与演变之道
读懂3D打印卓越与演变之道